JetBrainsがコード特化AI「Mellum2」公開
JetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI Pipelines
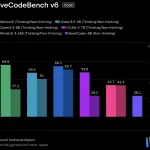
JetBrainsがコード生成などに特化した高速AI「Mellum2」を公開。他のAIと連携し、ソフトウェア開発の作業を効率化する重要なモデルです。
JetBrainsはMellum2をリリースし、その重みをApache 2.0ライセンスの下でオープンソース化しました。Mellumの最初のバージョンは、補完に特化した4Bの密なモデルでした。Mellum2はその後継であり、ソフトウェアエンジニアリングに特化した汎用モデルです。コード生成と編集、デバッグ、多段階推論、ツール使用と関数呼び出し、エージェント的コーディング、会話型プログラミング支援をカバーしています。JetBrainsチームはMellum2を「中心モデル」として位置付けています。これは、フロンティアモデルの単独の代替ではなく、より大規模なAIシステム内の高速で専門的なコンポーネントです。 Architecture Mellum2は、合計12Bのパラメータとトークンあたり2.5Bのアクティブパラメータを持つMixture-of-Experts(MoE)アーキテクチャを使用しています。MoEモデルでは、各トークンでパラメータの一部のみが実行されます。このモデルには64のエキスパートがあり、トークンあたり8つをアクティブにします。これにより、トークンあたりの計算量は2.5Bの密なモデルと同等に保たれ、合計パラメータ数は専門化のためのより高い容量を提供します。主なアーキテクチャの詳細:レイヤー:28 隠れ層サイズ:2304 MoEエキスパート:合計64、トークンあたり8つをアクティブ アテンション:32のクエリヘッドと4のKVヘッドを持つGrouped-Query Attention(GQA) スライディングウィンドウアテンション(SWA):4つのレイヤーのうち3つに適用され、ウィンドウサイズは1,024です。残りのレイヤーではフルアテンションが実行されます。コンテキスト長:131,072トークン Multi-Token Prediction(MTP)ヘッド:補助的な事前学習目的として、また投機的デコーディングのための組み込みドラフトモデルとして機能します。精度:bfloat16 語彙サイズ:98,304 このモデルは自然言語とコードを扱います。マルチモーダルではありません。画像や動画入力はありません。 Pre-Training 事前学習は、3段階のカリキュラムを通じて約10.6兆トークンに及びます。データ混合は、3つのフェーズにわたって、多様なウェブコンテンツから厳選されたコードおよび数学コンテンツへと段階的に移行します。トレーニングには、MuonオプティマイザーがFP8ハイブリッド精度で、線形減衰をゼロにするWarmup-Hold-Decay学習率スケジュールとともに使用されました。事前学習後、ベースモデルは
この記事について質問
記事の内容に答えます。記事外のことは都度ウェブで調べます。