AIが数学問題を検索・分類
Building a Semantic Search Engine and Open-Status Classifier over the ResearchMath-14k Dataset
AIが数学の難問を意味で検索し、未解決かどうかを判別するシステムを構築。研究者が効率的に関連問題を見つけ、研究を加速させるのに役立ちます。
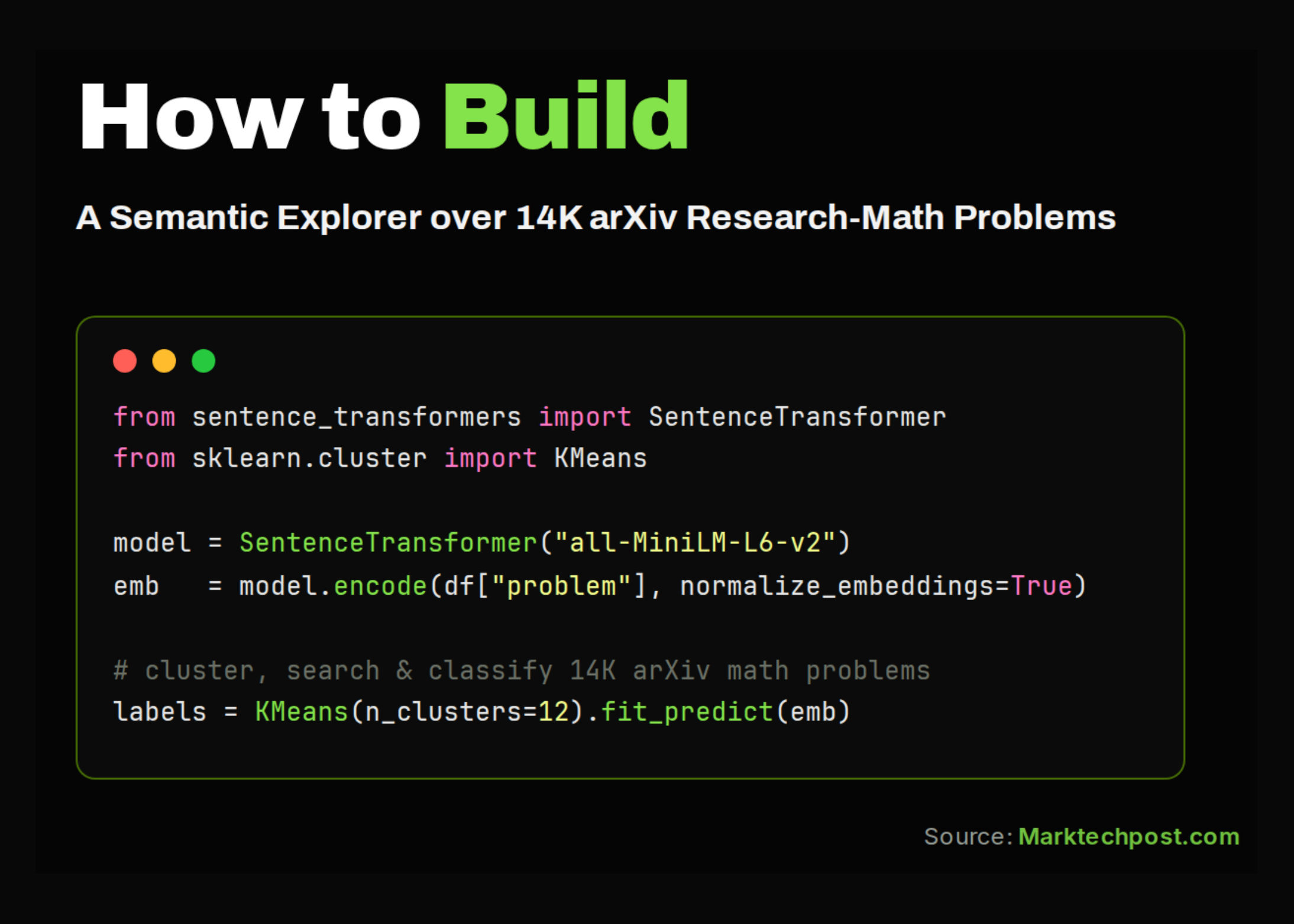
このチュートリアルでは、arXivから採掘された研究レベルの数学問題のコレクションであるamphora/ResearchMath-14kデータセットを扱います。私たちはデータセットをロードし、その構造を検査し、数学分野と未解決ステータスのカテゴリにわたって問題がどのように分布しているかを調査します。その後、基本的な分析を超えて、分野固有のキーワードを抽出し、semantic embeddingsを生成し、問題の状況を視覚化し、関連問題をクラスタリングし、データセット上にシンプルな検索エンジンを構築します。また、embeddingsから問題のステータスを予測し、密接に関連する問題やほぼ重複する問題を検出するためのclassifierを訓練します。!pip -q install -U datasets sentence-transformers scikit-learn umap-learn \ pandas matplotlib seaborn wordcloud 2>/dev/null import warnings, numpy as np, pandas as pd warnings.filterwarnings("ignore") import matplotlib.pyplot as plt import seaborn as sns sns.set_theme(style="whitegrid", palette="deep") SAMPLE_SIZE = 4000 RANDOM_STATE = 42 EMB_MODEL = "sentence-transformers/all-MiniLM-L6-v2"私たちはまず、必要なライブラリをインストールし、分析、視覚化、embeddings、データ処理に必要なツールをインポートします。また、サンプルサイズ、乱数シード、embedding modelを含む主要な設定値を設定します。これにより、ResearchMathデータセットを操作する前にクリーンなセットアップができます。from datasets import load_dataset ds = load_dataset("amphora/ResearchMath-14k", split="test") df = ds.to_pandas() print("Rows:", len(df)) print("Columns:", list(df.columns)) df.head(3) TEXT_COL = "self_contained_problem" df = df[df[TEXT_COL].astype(str).str.len() > 20].reset_index(drop=True)私たちはHugging Faceからamphora/ResearchMath-14kデータセットをロードし、pandas DataFrameに変換します。行数、利用可能な列、およびいくつかのサンプルレコードを検査して、データセットの構造を理解します。その後、意味のある長さの問題文のみを保持します。
この記事について質問
記事の内容に答えます。記事外のことは都度ウェブで調べます。